I have a huge media collection, that I created many years ago. Eventually, in some time I got need to find several files by their names. After unsuccessful checking tens of my CDs I realized, that it was too complicated to do that simple task as my media collection was just too big. In this way, I came to the conclusion, that I needed a media cataloging tool.
I tried many ready solutions, but none of them appeared to be good enough for me to use. The biggest problem with them was the search – it was just damn too slow. And, it was so slow becauses they used plain text files, e.g., in XML format, to store the file structure information. It looked like they loaded those big text files, parsed them and then made the search. And they did that for each media. So eventually, I realized, that I had to implement my own solution.
Requirements
I started with defining the requirements for the media cataloging tool:
- Each media should be stored in separate file(s) named after the media. In this way, it should be possible to copy information (to a different computer) about selected media only.
- Any additional data, such as information about audio tracks (for MP3), should be stored in separate files as well. In this way, it should be possible to copy the information about the file structure and specific additional data only. The database viewing tool(s) should be able to handle the situation, when the additional information is unavailable.
- Searching media should be fast. This means, that any text format is not acceptable. This does not mean, however, that the search should be extremely fast (i.e., use of binary trees is not needed), just not as slow as it’s for textual files.
- Viewing tool(s) should have as less dependencies as possible. I might need to have them installed on a server, where installation of MySQL, PostgreSQL and so on could be undesirable. So, this meant, that the solution should use an own binary format.
- The whole database should not be too big. At least, it should not be big, when all additional data, such as information about audio tracks, are removed.
- It should be possible to browse the media collection using the console. At that time I was a system administrator (in addition to a developer), so I often needed to check the media collection remotely, e.g., through SSH.
- Finally, the solution should work on (Debian) Linux. I don’t use any other operation systems, so I don’t need them to be supported.
In general, the idea was to implement a file-based media cataloging tool. This was inspired by the Unix style of storing state information (or by something like this – I don’t remember to be honest), where every separate bit of data had its own location and could be manipulated without affecting other bits of data.
Implementation
The first version of the media cataloging tool, which got the name CD-Index, was implemented around 8 years ago. That version was for 32-bit Linux and supported additional data only for MP3 files (it also stored paths for symbolic links as additional data). The tool was also able to index many archive formats including (but not limited to) TAR, ISO, ZIP, RAR, DEB and RPM.
Recently, I finally got some free time to port the tool to 64-bit Linux and to implement support for additional data for images and videos, what I wanted to have for a long time already (since I moved to 64-bit system, at least). With the new features I needed to reindex almost all my media, so I got a chance to test it quite well and to fix many old and new issues. As a result now CD-Index works like a charm.
Features
So, here is the full list of what the tool is currently able to do:
- Each independent type of information is stored in a separate file, thus image data are stored in CDP files, video data – in CDV and CDVA files and so on (see also below). Any of these additional files can be removed without damaging the database. In this way, users can easily control size and types of information in their media database.
- The file structure information is stored in CDI files (“I” for “index”). Symbolic links information, as it has already been mentioned, is stored in CDL files (“L” for “links”).
- The tool extracts meta information from MP3 files. Unfortunately, currently it supports only IDv3 tags. The extracted information is stored in CDA files (“A” for “audio”).
- The tool also extracts meta information and generates thumbnails from image files. Currently supported image formats are JPEG, PNG, GIF, TIFF, SVG, XCF, PSD, BMP, ICO, NEF, CRW and CR2. The meta information is stored in CDP files (“P” for “picture”). Thumbnails are stored under the subdirectory, which has the same name as the main CDI file (without extension). The format of the thumbnail is JPEG and the name is the numeric ID of the file in the CDI database (e.g.,
123.jpg). To extract meta data and thumbnails from images the tool uses GraphicsMagick. - The same – extracting meta information and generating thumbnails – is supported for video files. Currently, this is done for AVI, MKV, MP4, MOV, MPEG, VOB, WMV, 3GP and FLY file formats. The extracted meta information is stored in CDV (“V” for “video”) and CDVA (“A” for “audio”) files. The latter store information about audio streams (multiple tracks are supported). Thumbnails are stored in the same subdirectory as the ones for images, but unlike image thumbnails there can be several thumbnails for one video file (usually, 3). The name of the thumbnail is the numeric ID and the sequence number, which are separated by dash (e.g.,
123-2.jpg). To extract the meta information CD-Index uses FFmpeg and to generate thumbnails – ffmpegthumbnailer. - As it was already mentioned, CD-Index is also able to extract the file structure information from many archive (and not only) formats. Thus, currently supported formats are TAR.GZ, TAR.BZ2, TAR.XZ, ZIP, RAR, ISO, CPIO, DEB and RPM. However, the tool does not extract any meta information from audio, image and video files, that are in such archives (it would need to unarchive them to do this). To read some archive formats CD-Index uses libarchive, for others it uses external tools (e.g.,
dpkg-debfor DEB). - Currently no (own) UI is available, but the media database can be browsed in Midnight Commander with the help of the
cdbrowsetool. Thus, to check the contents of a media (after properly configuring Midnight Commander, of course) the user can just press Enter on the media’s CDI file. And, to check the meta information of a file on the media the user can just press F3 (but, it can also be needed to press F8 to prevent MC from trying to read metadata from that file by itself). The meta information will also include paths to thumbnails, if they are available.
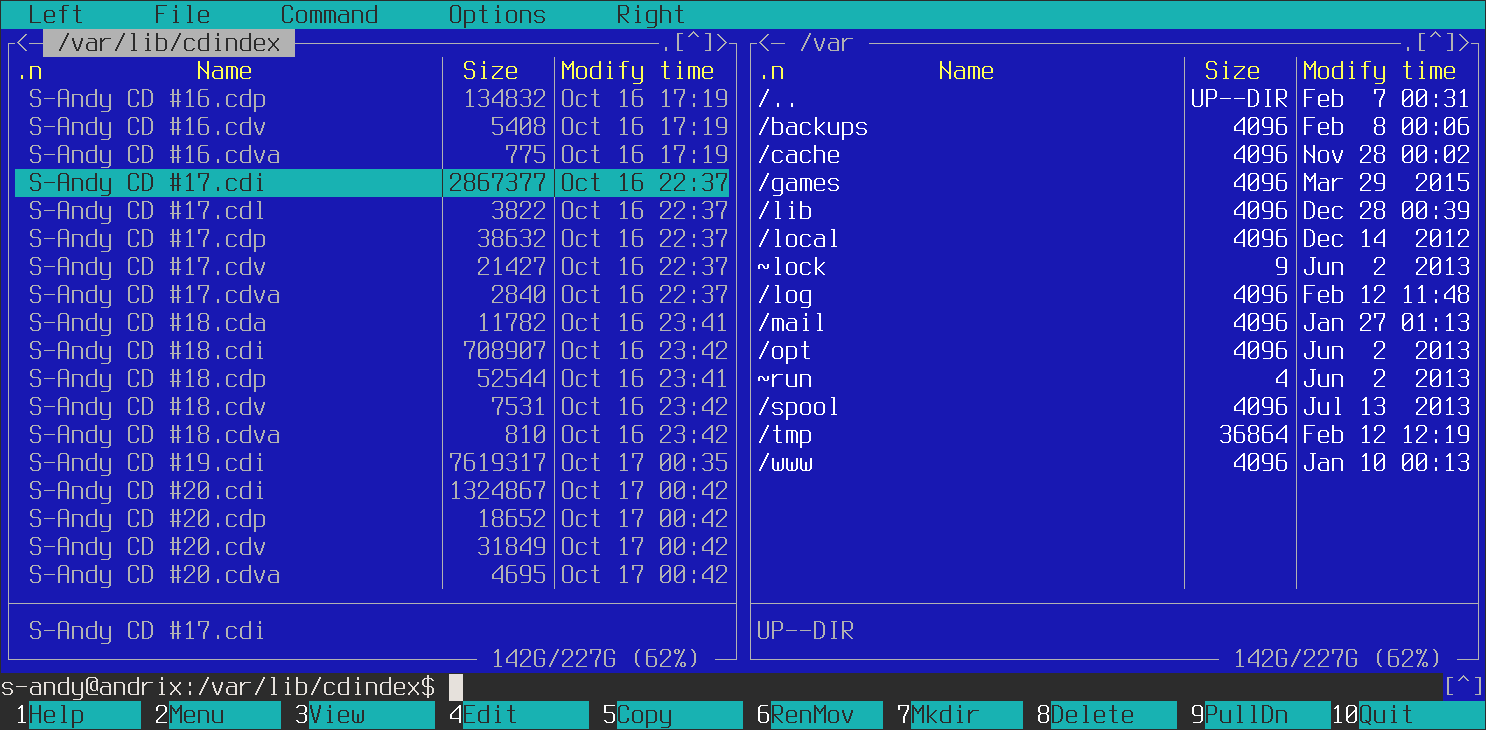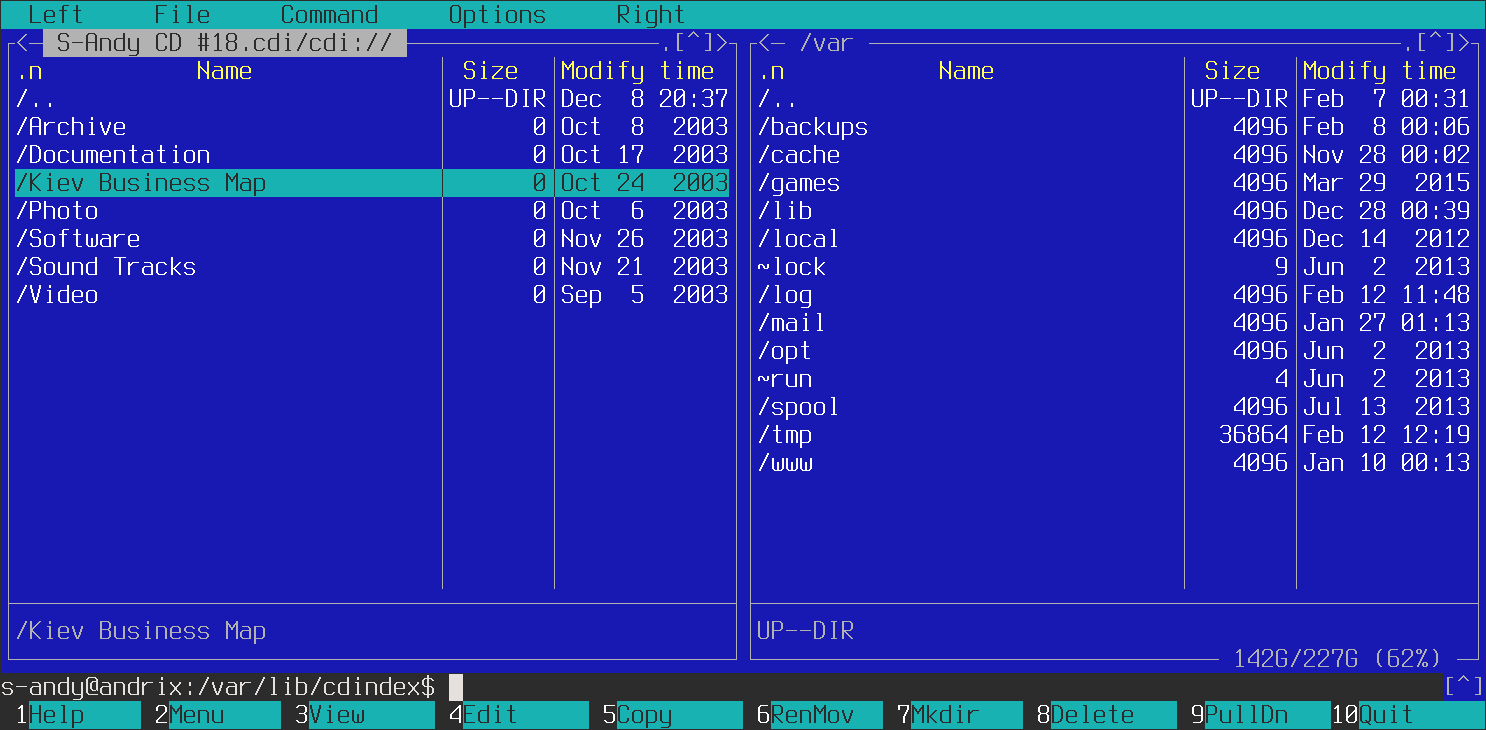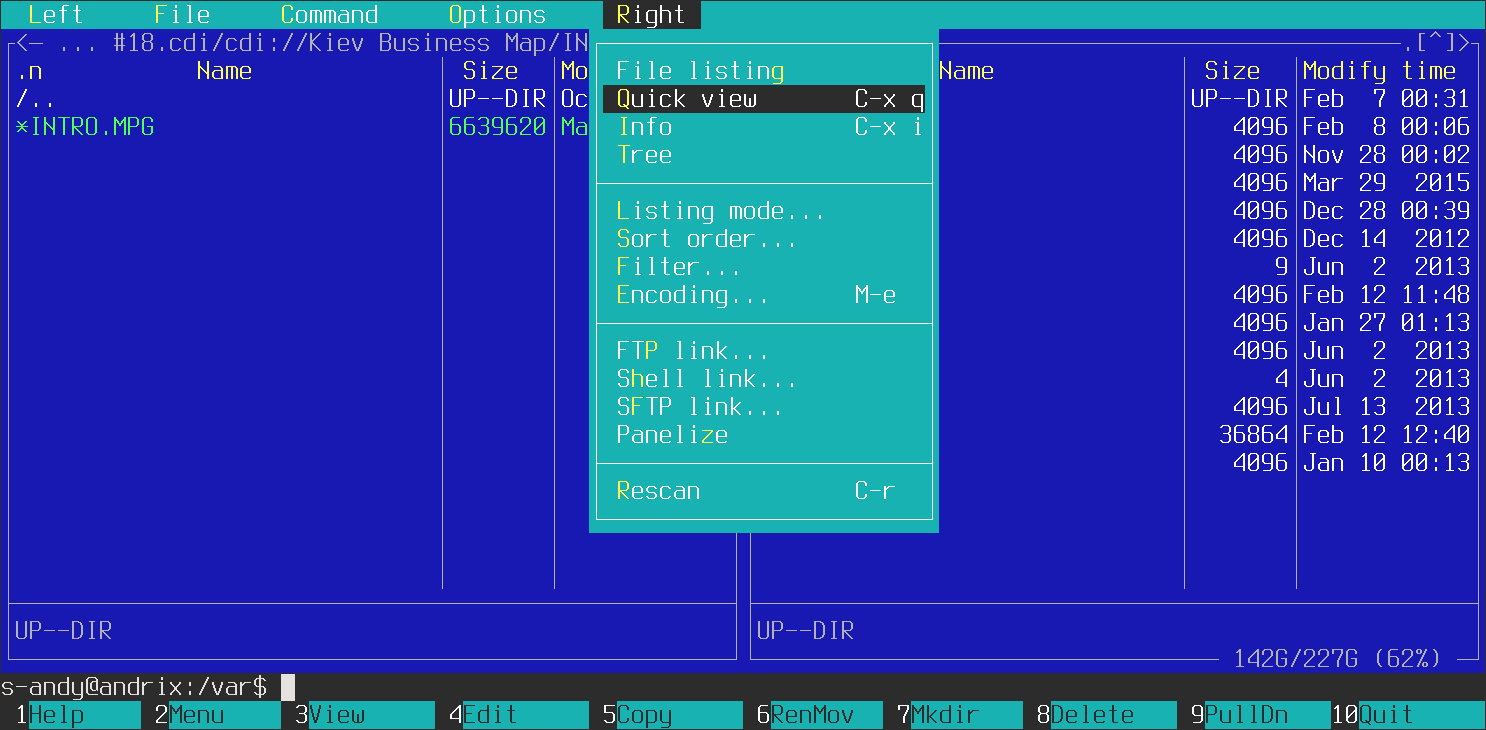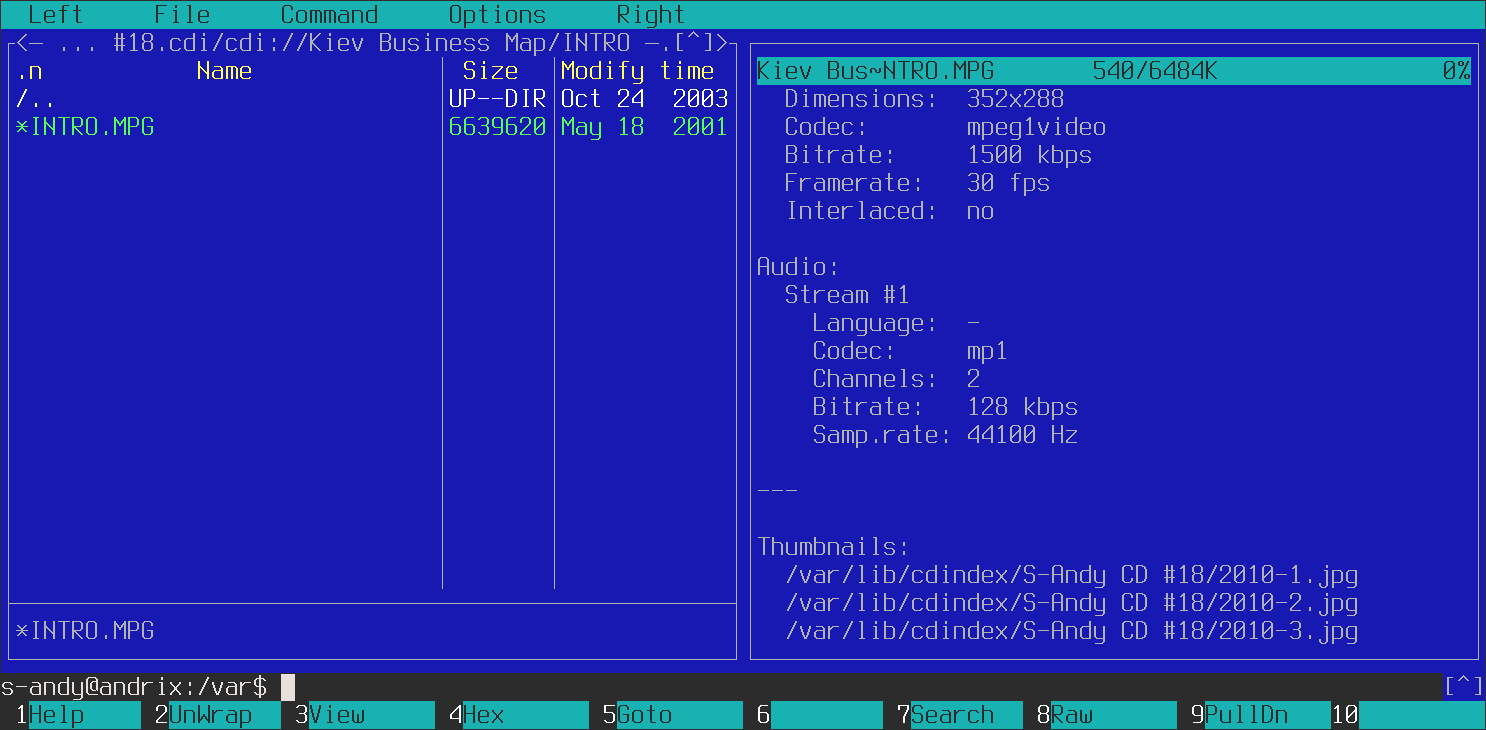
- The general information about the media, such as the date and volume label, can be checked with Midnight Commander too just by pressing F3, when the corresponding CDI file is selected (if MC shows raw file contents, users will need to press F8 to make it call the
cdbrowseutility to process the CDI file). Of course this should be properly configured beforehand as well. - The two above-mentioned features makes UI, in fact, available. Currently, it’s console- (MC-) based only, but this can be treated as an advantage, as no graphical environment is required for the tool to work and this makes it possible to use it remotely, e.g., via SSH. Of course, such UI is far from being full-featured (e.g., to check thumbnails users will need to load them into an image viewer manually), but…
- Fast search in the database (in all media or in the selected ones only) can be performed using another console-based tool called
cdfind, which was designed to resemble the standard Unix toolfind. Thus, CD-Index’scdfindsupports suchfind‘s options as-name,-iname,-regex,-iregex,-type,-size,-mtime,-atimeand-printf. In this way, users familiar with thefindtool (i.e., most administrators) should be able to search files in the CD-Index database without learning syntax ofcdfind. - Finally, to index new media users will use the console tool
cdindex. This is the tool, that extracts meta information and thumbnails, indexes archives and so on. Depending on what it finds on the media, this tool creates CDI, CDL, CDA, CDP, CDV, CDVA files and the subdirectory with thumbnails.
Future
CD-Index was first written about 8 years ago. After that there was a huge 7-year-long (approximately) pause. Recently it was revived and got many new interesting features. There are also plans to implement more cool features (see issues and below), but, unfortunately, I can’t guarantee, that this won’t be after other 7 years. But, what I’m sure about is that the tool won’t be abandoned and I’ll continue to work on it, even if this will be in 7 years.
So, let me tell you, how do I see the future of this tool and what other features I’d like it to have:
- The most important thing, which is currently missing (it can be told so), is UI or front end. The UI should be independent and not required by other tools. To preserve the ability to work with the media database remotely, the UI is better to be web-based. In this case, there should be some PHP library, that can be used to develop such front end. I think, this can even be a PHP module, written in C, which will use a special CD-Index library to work with the database (such library is to be created too).
- But, I would also love to see a desktop client (UI). I prefer this to be written in QT and C++ (for KDE – as this is the desktop environment, that I’m using). For this, the aforementioned CD-Index library will be needed too.
- A better control over the indexing process is needed. Thus, it should be possible to skip thumbnails for some or all image and video files.
- The
cdfindtool is to be extended to support meta data. For example, I want to be able to search for video files, which include an audio stream with Ukrainian translation (likecdfind -video-audio-translation ukr).
Comments
Also available in: Atom
Add a comment